
Posted on 2020-04-29 by Matt Strahan in Business Security
There I was again, staring at the report. In each security issue in our penetration testing and compliance work we have our risk assessment rating which is a pretty simple process based on ISO 31000. You identify the risk, figure out the likelihood and impact, and then use the risk matrix to give it a risk rating. Although a fair few companies now have their own risk matrix which we are happy to use in our reports for them, our standard risk matrix looks like this:
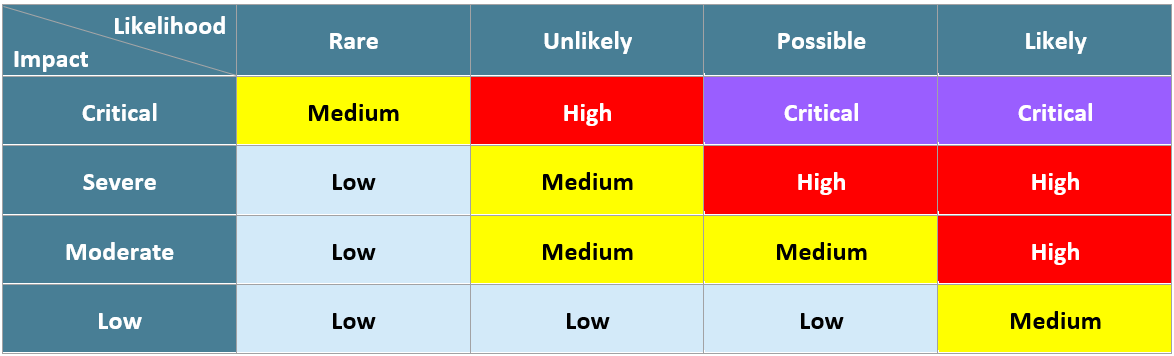
It should be a simple enough process, yet still I am left staring at the report thinking “how likely is it that this company will get hacked using this vulnerability?”
Interestingly when doing Business Continuity Management we often have clear answers here. Take your standard NAS. You have, say, five discs managed in a RAID 5 configuration where if one drive goes down it’s OK, but if two drives go down it’s potentially disastrous. Each of those drives has a published “mean time between failures” that is based on real world testing. You can also time how long it would take to replace the drive and rebuild the RAID. With a bit of maths using those pieces of information, you can actually get a pretty good number as to the likelihood the RAID will be destroyed, often accurate to several decimal places.
(As a sidenote here, even that best-case example has a few caveats. For instance, drives purchased together, made in the same batch, have a nasty habit of failing at the same time!)
Hacking feels different. There’s a lot more uncertainty and a lot less data.
The likelihood rating
Here’s where I let you in on a secret in the security industry. The likelihood rating given to security issues in all sorts of risk registers is an educated guess at best. At worst, it’s manipulated to give the “right” risk rating at the end of the risk assessment process. Let’s look at these two possibilities separately.
As a security professional, when assigning a likelihood I would look at a range of factors. These include:
- The skill required to exploit the vulnerability;
- The visibility of the vulnerability – how hard we had to look to find the vulnerability;
- Instances of the type of vulnerability being used in public attacks – is it currently fashionable;
- If there’s any inside knowledge required to find or use the vulnerability;
- If authentication is required and, if so, what level of authentication.
Unlike the RAID example, there’s no maths here. Each component of this is based on the judgement of the security professional and can only be made more accurate by the experience and knowledge of the security professional. There are no actuarial tables in the background, and no relevant studies to pull probability data from (after all, with the ever changing industry relevance fades at record speed).
What’s more, in each component there’s a huge amount of uncertainty and the likelihood can change at a moment’s notice.
- The skill required to exploit the vulnerability: Oh wait someone released a metasploit module the day after we gave you that report. Sorry it’s point and click now.
- The visibility of the vulnerability – how hard we had to look to find the vulnerability: Turns out someone just stumbled on it. You know how you’re looking for your keys and it takes ages to find them but then your wife comes in and just spots them straight away? Yeah that happened but instead of finding your keys you’ve been ransomwared.
- Instances of the type of vulnerability being used in public attacks – is it currently fashionable: It wasn’t fashionable yesterday but with the new metasploit module it is now!
- If there’s any inside knowledge required to find or use the vulnerability: Turns out that one of your employees did up a blog post. He didn’t know it, but the topic was “how to hack your organisation”. The inside knowledge suddenly wasn’t so inside anymore.
- If authentication is required and, if so, what level of authentication: Turns out Jonny keeps his password on a post-it note on his monitor. You didn’t realise because you thought that a post-it note saying “Password” was a joke.
And under all this uncertainty the likelihood is assigned.
This is not a problem that is unique to penetration testing. Cyber security insurance has to form accurate likelihood ratings just to settle on a premium to charge. The actuarial tables aren’t there and the situation is constantly changing.
And yet you have to rely on something. You need some way to figure out what is important and so we have to use our professional judgement to make a sensible choice on the likelihood.
Manipulating the likelihood
This all brings us to the worst case scenario. Due to policy requirements to fix vulnerabilities above a certain rating, or due to “CYA security” it becomes tempting for people with an agenda to manipulate the likelihood.
If you want to change the final rating, it’s much harder to manipulate the impact because the impact can often be based on real world data. If a bank account holds $100,000, then the direct impact of that bank account being emptied will be $100,000. Although the impact of things like negative press coverage, brand impact, and reputation damage can be harder to define, it’s also a bit harder to cover up as non security professionals usually understand “brand damage” and can often see through the justification. Although there’s plenty to say about the impact of a technical vulnerability (which will surely come in another post), the impact is still harder to manipulate.
The likelihood then is more likely to be fiddled with. Someone could say, for instance, “this is a particularly hard vulnerability to exploit” and then assign a lower likelihood rating. “Someone exploiting an SQL injection on the front page of our site? Never gonna happen. You need to have skills for that!” Unless the listener knows how to exploit the vulnerability, how could they say whether it’s easy or hard? How can they spot the rubbish and manipulation?
The manipulation of likelihood ends up with High being instead rated as Medium, and Medium being rated as Low. Although I feel putting forward a rating you don’t really believe should be something to be ashamed of, it happens too often because, after all, the likelihood was a professional judgement based on an uncertain environment. How were we to know?
I believe that the assignment of a likelihood rating is one of the most important reasons to bring in an independent third party to provide testing and assessment. Otherwise someone with an interest assigning a particular rating might be changing the likelihood based on convenience even if they’re not trying to be manipulative.
It also brings me to a simple policy rule we have in place:
The likelihood and impact ratings must not be changed due to client requests, unless the client provides new information that changes the professional judgement of the tester.
There’s additional guidelines you can read about in our Penetration Testing Engagement Guide, but that’s the big one. Even if the likelihood is professional judgement rather than based on actuarial tables and fixed probabilities, it’s important that the professional judgement is maintained and our integrity is maintained. This way we’re shining light on the real issues and making sure that our judgement can be trusted.
About the author
Matthew Strahan is Co-Founder and Managing Director at Volkis. He has over a decade of dedicated cyber security experience, including penetration testing, governance, compliance, incident response, technical security and risk management. You can catch him on Twitter and LinkedIn.
Photo by Clint Patterson on Unsplash.
If you need help with your security,
get in touch with Volkis.
Follow us on Twitter and
LinkedIn